Crunchyroll
I began as a Senior Secure Application Engineer in 2017 and was skip promoted past staff engineer to Application Architect after 18 months.
Below are a few of my contributions
Subscription Processing System
When I started at Crunchyroll, I joined a team of 6-8 engineers building a new subscription processing system for a subscription video on demand (SVOD) service with 2 Million subscribers. Building a multi-tenant system to process over $10 Million a month in credit card transactions presents a number of challenges.
The systems being replaced were single tenant apps written in PHP having undiagnosed edge cases and known defects. A new multitenant system was envisioned to replace both systems in Go.
A few things I did on the project:
-
Designed the Database Schema
The project had some architectural diagrams, but the data model was vague.
I Created an ERD in MySQL Workbench (15 tables) and socialized it with the team.
After several compromises and iterations we came to a workable solution (12 tables).
I also convinced the team to adopt standard columns (id, created, modified) and strong foreign key constraints.
-
Simplified the Architecture
The original architecture called for 9 microservices and 4 queues.
I was able to reduce that number to 4 microservices and 1 queue.
-
Rebuilt the background workers
The team had attempted to create a background worker system.
It ran on everyone's VM except mine (because mine uses 2 CPUs).
I spent 2 days trying to fix its architecture to prevent race conditions.
I gave up trying to fix it and built a simpler thread safe version in 2 days.
-
Explored edge cases
The system supported multiple concurrent recurring subscriptions per user.
It also prorated new subscriptions in order to batch subscription processing.
So if you had 3 subscriptions, they would all renew on the same day of the month.
Combined with payment failure scenarios and retry schedules, things could get complicated.
I successfully advocated for a centralized subscription state to prevent systemic inconsistency.
-
Worked with the Data team
There was obviously a lot of important reporting data generated by the system.
I worked with the data team and made schema changes to enable easier reporting.
-
Created a migration plan
The existing system was known to have accounts in weird states due to edge cases.
For this reason, I advocated for a per-user migration strategy.
Users were migrated one at a time from the old system to the new system in batches.
The first batch was internal employees in order to prevent user disruption.
Then accounts were migrated to the new system in batches of 10,000.
Site Reliability Engineering
The weekend after I started, the website went down for several hours on a Saturday night when a new episode of a popular series went live. As a member of the Secure Apps team, I was confident that the systems for which I was responsible were not the cause of service disruption. Nevertheless, I took it upon myself to investigate the stability issues to see if I could help other teams pinpoint the source of the problem.
After a few hours sifting through NewRelic, Cloudwatch and access logs, I had a good understanding of the various service resiliency failures and decided that the application's stability issues could be fixed with a microcache.
So, that weekend, I went home and I wrote an open source embedded HTTP cache in Go.
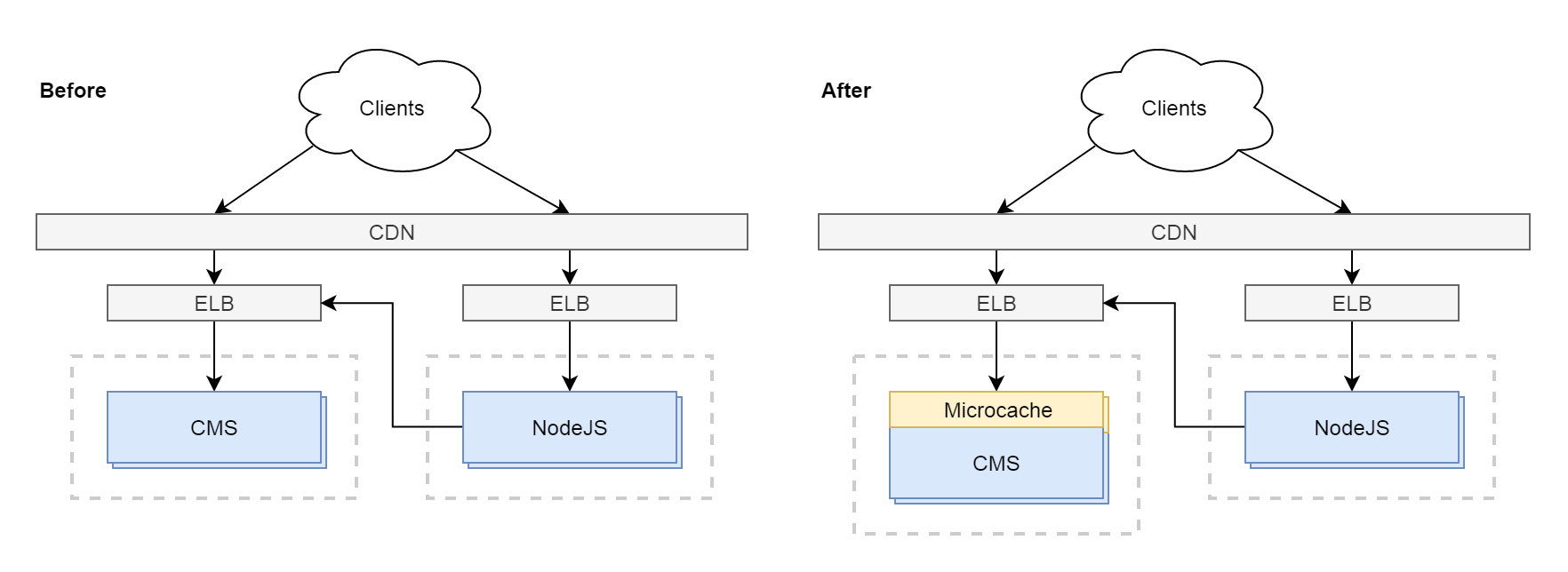
- Client requests HTML page from NodeJS containing ReactJS app
- NodeJS calls to internal CMS API to prefetch data
- Client receives HTML page
- Any data not prefetched by NodeJS is fetched from CMS API directly
A strong 5 minute TTL on API responses in the CDN protected the external API from traffic bursts. However, these protections were not available on internal API calls from NodeJS which were routed directly to the scaling group's load balancer.
The NodeJS app also had a 6 second timeout such that it would attempt to fetch data from internal APIs for up to 6 seconds at which point a response would be returned to the client regardless of how much data had been collected. This was problematic because there was no thread shutdown on timeout so after that 6 second timeout was breached for a request due to downstream latency during high traffic, outstanding requests would continue to be sent to downstream internal APIs even after a response had been returned to the client.
This abberant behavior resulted in a request multiplication feeback loop ensuring that if any of the system's internal APIs ever experienced increased latency for any reason, the entire application would beat itself to death with duplicate requests.
With no additional infrastructure, the http caching middleware was integrated into the API and it never failed in the same way again.
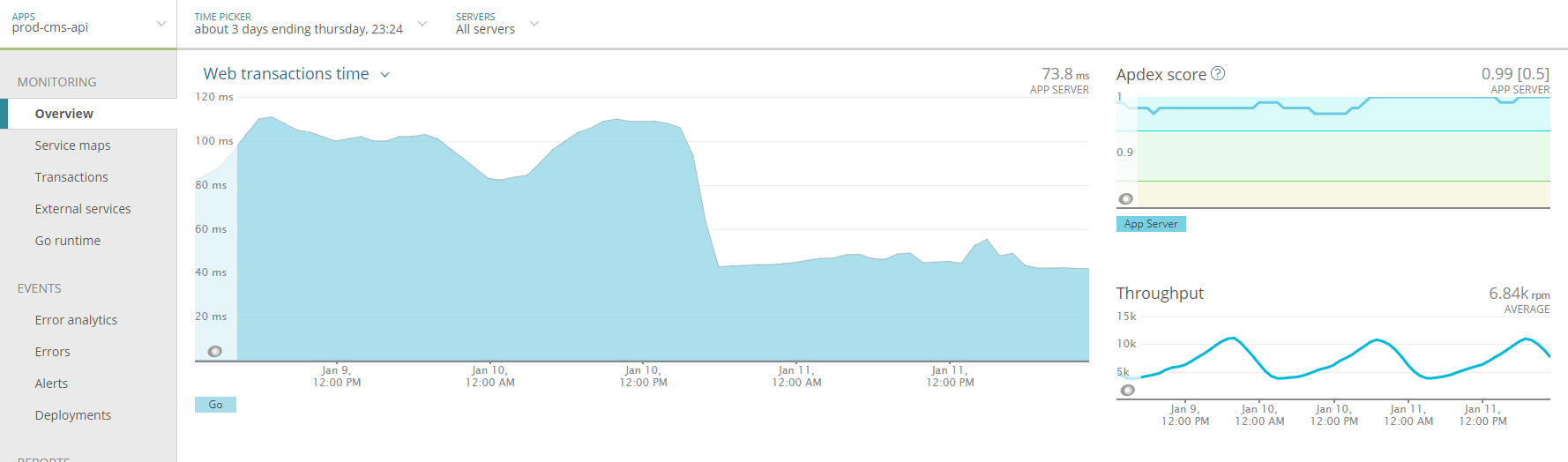
A few weeks later, the front-end team introduced an error to production which effectively doubled the traffic to the API. This sudden traffic spike caused no service disruption thanks to the cache and actually improved the efficiency of the API.
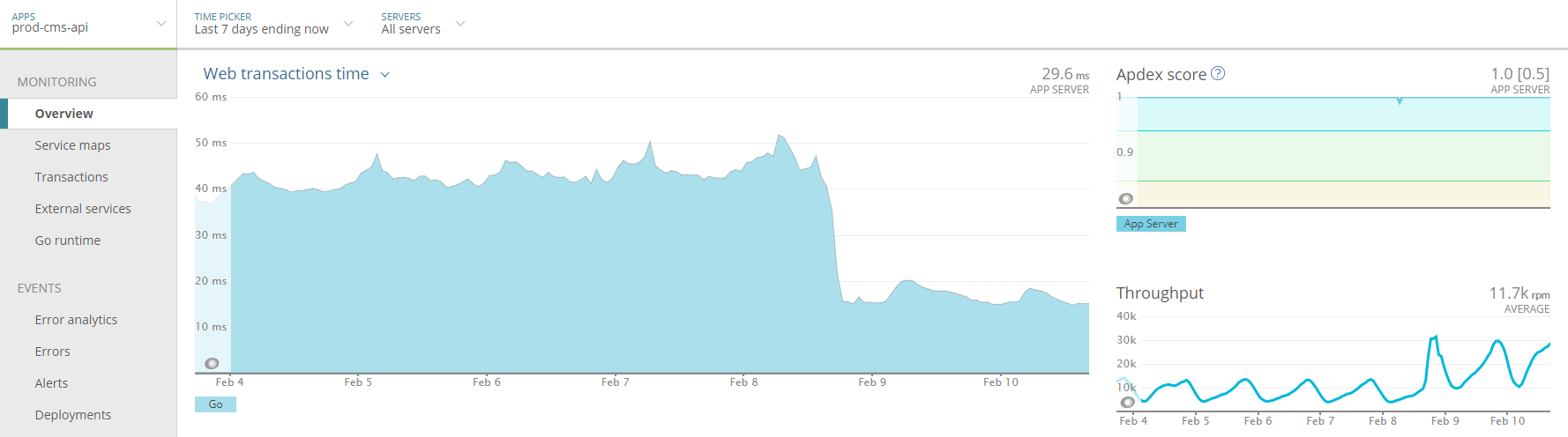
I jumped in to fix the problem without being asked to do so because where I come from, engineers take notice when the website goes down.
Third Party Integration
The first project I lead at Crunchyroll was a third party integration with AT&T.
Basically, AT&T would run a promotion offering some of its premium subscribers a free subscription to Crunchyroll's video on demand service.
As the project's tech lead, I:
- Worked closely with product to gather product requirements
- Generated engineering requirements with a multi-phase schedule
- Managed communication and tracked deliverables with external parties
- Created architectural diagrams and proposed new microservices
- Created new microservices and infrastructure automation to support them
- Participated in conference calls with outsourced external teams in India
- Helped debug architectural security flaws in external systems
- Created test plans and coordinated QA access across staging environments
- Worked with Data team to provide adequate information for reporting
- Worked with finance team to devise invoice pipeline based on reporting
- Created SFTP endpoint with static IP for backend integration
QA was fun. AT&T actually sent us batches of SIM cards linked to accounts in various states in the mail that we would need to insert into phones in order to perform end to end testing. This applied a physical limitation to the number of end-to-end tests we could run and completely decimated any hopes of automated cross-organization integration testing. Internal automated unit and integration tests ensured that things on our end continued to operate as expected.
Integrating with large established enterprises requires plasticity.
It would have been nice if they had integrated with our API rather than delivering information via SFTP, but in the end it wasn't worth the fight. We were the smaller, more agile company and it made a lot more sense for us to build a one-off SFTP drop point to work with their existing systems than to ask them to integrate with us. Bending to the will of giants yielded a more stable system built in less time.
Microservice Standardization
Much has been written about microservice standardization in Go.
There are a million different ways to structure a repository. Some people in organizations with many teams and dozens of microservices spend a lot of time debating what is the best package structure for microservices on the premise that consistent package structure is important. This is true to some extent, though I felt as an application architect that the behavior of the services was more important than their structure.
If you can establish a set of architectural constraints that everyone can agree to, you end up with a shared set of concerns that every service must address. This can be developed into a common set of interfaces that span the entire organization.
- Microservices MUST produce error logs.
- Microservices MUST be configured for log centralization (ELK).
- Microservices MUST NOT produce access logs. Those come from ELB -> S3.
- Microservices MUST use log levels.
- Microservices MUST set log level to WARN in prod.
- Microservices MUST set log level to INFO in stage.
- Microservices MUST use log levels appropriately.
- Microservices SHOULD integrate with NewRelic (excluding some very high traffic APIs).
- Microservices MUST use config files and not cli flags for runtime config.
- Microservices MUST set User-Agent header for all downstream internal API requests.
- Microservices MUST set an http timeout for all downstream internal API requests.
Systemic interface standardization reduces the learning curve for coming up to speed on a new service and it also reduces the total amount of work required to create a new microservice. This improves the quality of the components because developers have more time to document and scrutinize their design. It can lead to increased coupling since a change in a shared library is more likely to affect multiple services, so care should be taken in selecting which portions of the application ought to be shared and which ought to be duplicated.
Generally speaking, a component should only be shared between services if it is needed in more than one place today (don't assume that it might be needed) and it can be broken down into a small number of immutable interfaces.
Event Collection System
Crunchyroll has multiple tenants feeding client and server side events to Segment. With billions of events per month, the pricing was becoming unreasonable at the same time that the business wanted to emit more events from more clients. Not all of these events needed to go through Segment. Segment only served as an intermediary between clients and S3 for the highest volume event types.
So, it was decided that events dispatched from the 20+ clients would be routed instead to an event collection service which would write all events to the data lake in S3 and proxy some events to Segment as necessary for product metrics.
As a co-lead of the project, I:
- Measured expected cost savings
- Created an architectural proposal
- Estimated development, maintenance and running costs (8 bil evt/mo)
- Created the service
- Added a user interface for QA
- Automated infrastructure provisioning
- Documented the new service
- Worked with client teams to integrate the new service
- Ran the service in dual-write mode in production
- Worked with the data team to validate incoming data
- Switched the new system to the system of record in production
The end result was an API capable of efficiently routing > 3,000 events per second. The only bottleneck was the number of kinesis shards which had not yet been fitted with a reshard lambda for autoscaling.
Efficiency
One important aspect of making this service efficient was the addition of batching. 80ms of artificial latency was added to the API in order to enable batch writes to Kinesis.
This graph shows the introduction of artificial latency.
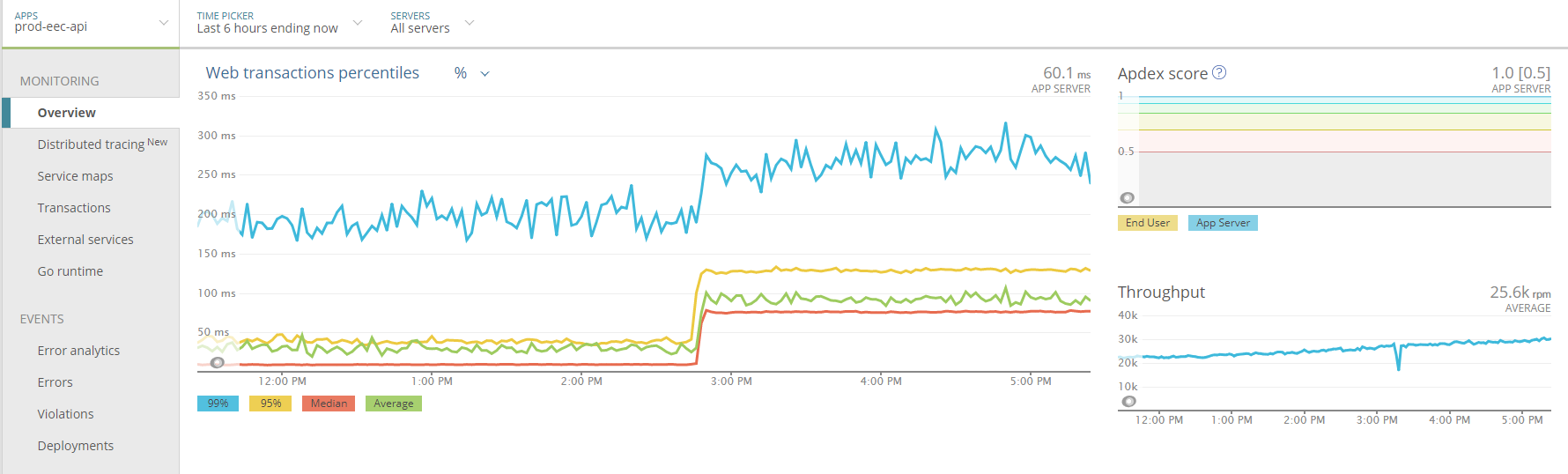
Below you'll see CPU time per request drop significantly after batching is introduced.
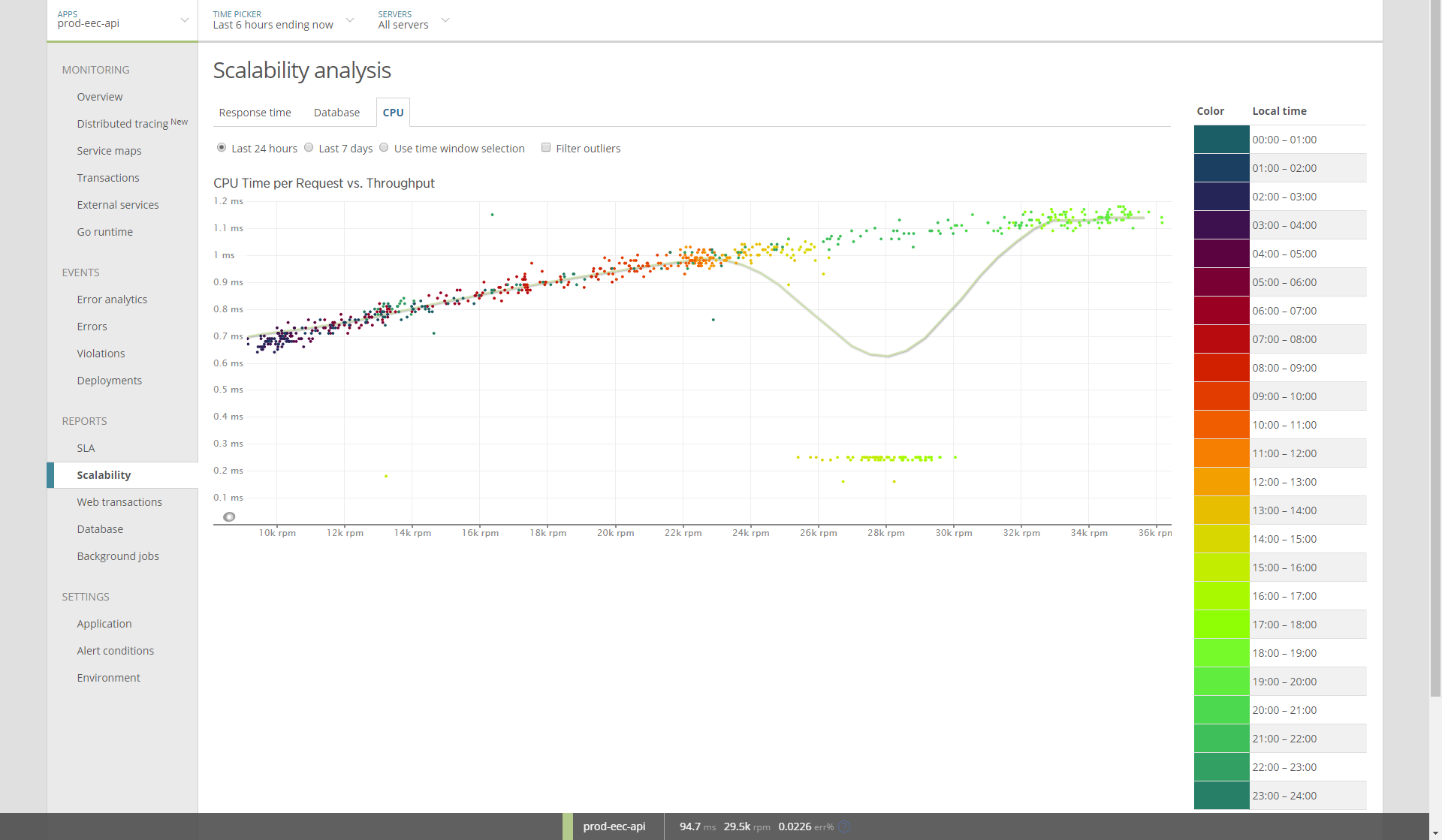
In fact, the trend is reversed. The service now becomes more CPU efficient under higher load due to batching.
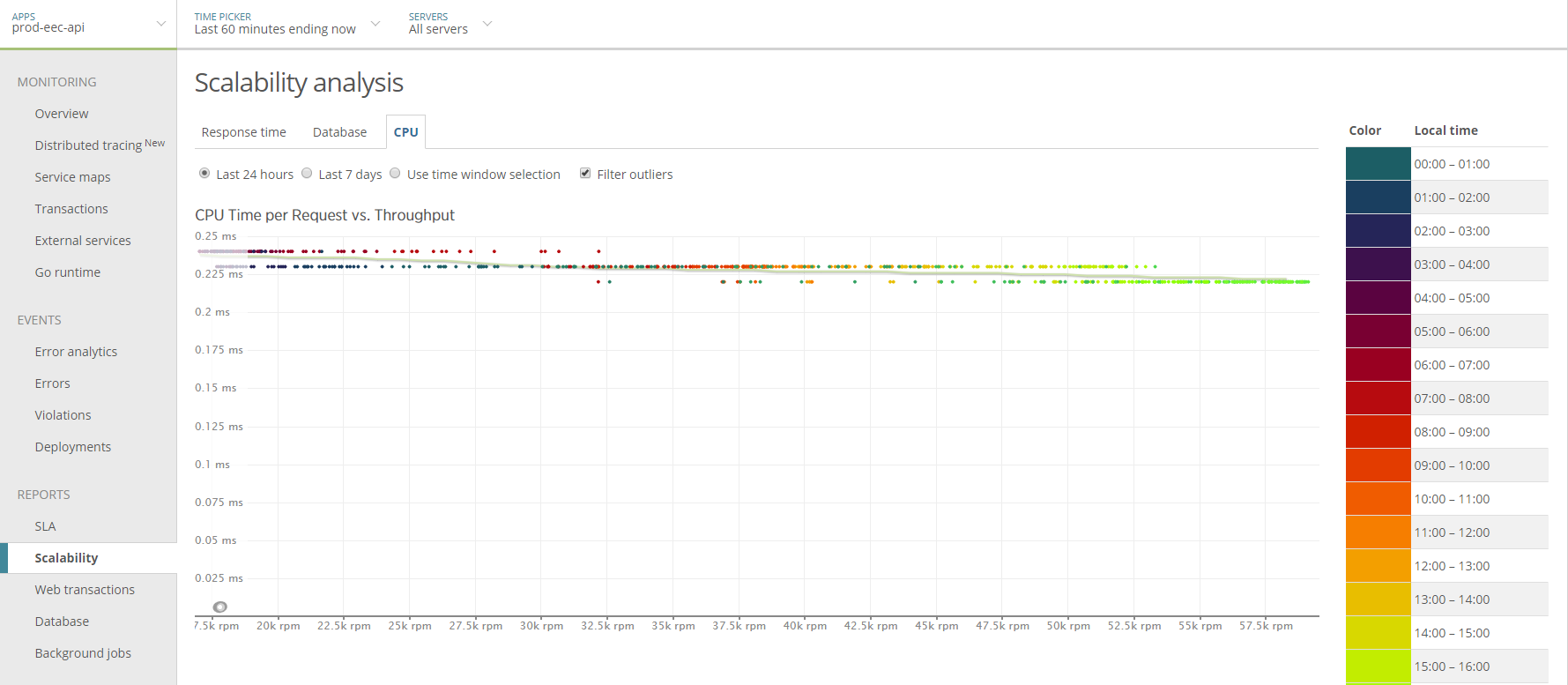
Scalability is not binary. Most would say that a service that scales linearly is a scalable service. And they'd be right. But I'd argue that there's a higher goal we should all aspire to and that's sub-linear scalability (illustrated above).
Batching is an easy way to acheive economy of scale in web service APIs.
Conclusion
Architecture is the thing that happens before the building. I quit Crunchyroll because the company's biggest projects for which I was refused any involvement in planning were headed toward certain disaster and as an architect I wasn't willing to accept responsibility for the architecture of new systems without having any involvement in their architecture. Rather than involving more technical leadership in the planning process, upper management decided to establish a new layer of non-technical project management between product and engineering which I perceived as a strong movement in the wrong direction. Since I left, the department has a new CTO and presumably a new direction. I enjoyed my time with Crunchyroll and wish them all the best.
Crunchyroll is a great place with a lot of amazing people.
Crunchyroll will always be a dearly beloved brand for Anime fans across the globe.